I've received an interesting question about whether it'd be possible to update https://github.com/geaxgx/depthai_hand_tracker so it'd work with multiple people instead of just one.
In my opinion, while it would be possible, it might be too slow. Body-prefocusing works by running person detection first, then it finds palms, and then hand tracker (palm keypoint/landmarks detection). The demo then doesn't run any of the first 2 NNs, only hand tracker NN, and it actually changes ImageManip crop rectangle based on where keypoints are on the frame, as shown on this flowchart (it's without the body prefocusing, which does person detection first):
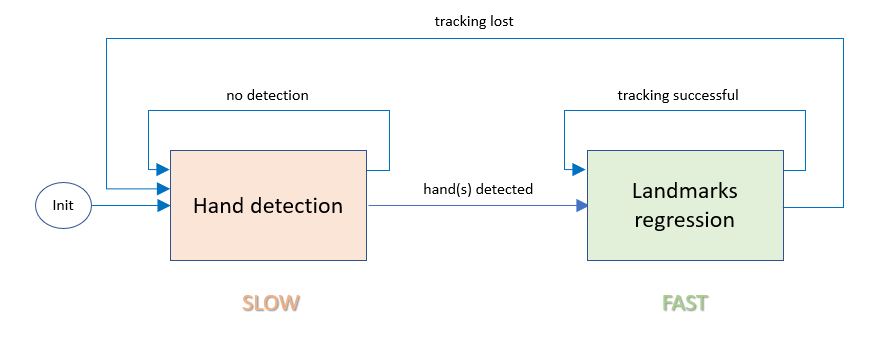
As hand tracker NN runs fast enough (and hands don't move that fast), you can get away with just running inference on 1 model, instead of all 3.
Adding support for multiple people wouldn't be that hard by default (looping through each person found, running hand detection NN, then hand tracker NN). But since AI resources would be split between 7 hands, it means FPS would also be one-seventh of what it previously was. That means that moving the hand even slowly would likely mean it wouldn't be found the next inference, which means the app would need to re-do the whole 3-NN based process to find all palms.
TL;DR while it would be possible to add multi-person support for hand-tracker demo, it would likely be too slow.



