I have converted part of the gen2-ocr code to C++ and run into an issue with sending images to text-recognition-0012.
The description of the NN says that it takes 120x32 frames and that's what the python code seems to be sending.
Doing the same thing in C++ results in the warning "Input image (120x32) does not match NN (1x120)".
Any suggestion to what could be behind this warning?
text-recognition-0012 in C++

I used the blobconverter tool to download using the same settings as the gen2_ocr demo uses apart from changing the openvino version to 2022.1.
It seems that the ocr model requires 2021.2 and running with that openvino version as well (the detection model is ok with 2022.1).
When doing that the warning goes away.
I guess that more must be needed to get a blob for 2022.1, perhaps using the omz_converter.
I compared the blobconverter generated files when only changing the openvino version and the content is different (basic compare) so something is happening.
My goal was to not use openvino 2021.2 since there is another warning for it being deprecated...
I'm pretty new to these "blobs" and how they are generated. Is there another converter step that needs to happen before the blobconverter or this model is just outdated with the new openvino?
It would be nice to have a "blob inspection tool" :-)
Hi dexter ,
Blobconverter basically uses OpenVINOs Model Optimizer (to convert to IR format) and Compile Tool . And besides blobconverter, you have a few options to convert the model to the blob, see docs here. Thoughts?
Thanks, Erik
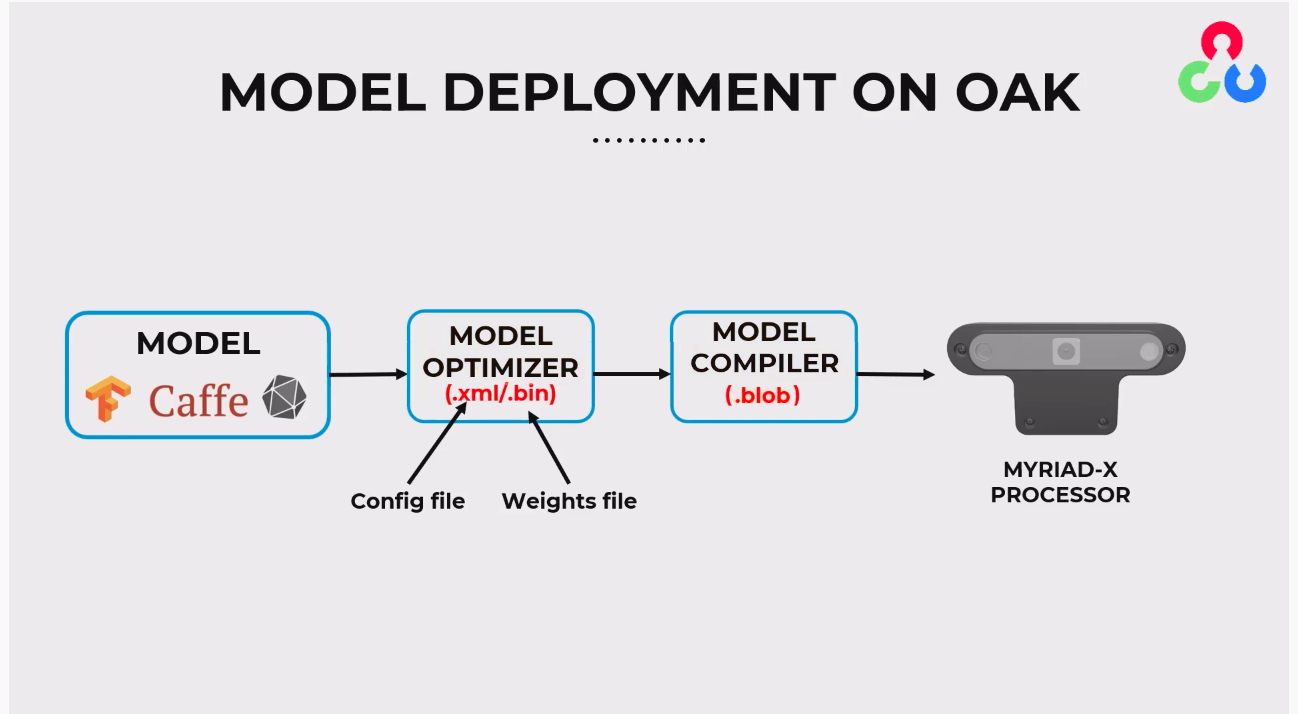
I found the xml/bin files and run the online myriad converter on them which reveals this error:
"The support of IR v5 has been removed from the product. Please, convert the original model using the Model Optimizer which comes with this version of the OpenVINO to generate supported IR version."
Sounds like the original model is needed? I haven't found any "source" other than the xml/bin (yet).
Hi dexter ,
Could you try to just download the model with OpenVINO 2021.4 form blobconverter app? Seems blob input/outputs are correct:
Inputs
Name: Placeholder, Type: DataType.U8F, Shape: [120, 32, 1, 1] (StorageOrder.NCHW)
Outputs
Name: shadow/LSTMLayers/transpose_time_major, Type: DataType.FP16, Shape: [37, 1, 30] (StorageOrder.CHW)Thanks, Erik
I tried the app you linked to for 2021.4 and it produces the exact same blob as when I use the local blobconverter and pick 2021.4. The generated file has some minor differences compared to generating for 2021.2.
I tried running with it and it works nicely. No deprecation warning for openvino and it works ok.
(I also tried the linked tool for 2022.1 and it created the same blob as before that doesn't work.)
The OCR results are not great so I'm tempted to try running with FP16 input instead of U8 to see if that helps. That means I have to figure out how to do "toPlanar" for FP16 which doesn't seem easy...
Hi dexter ,
The U8 input actually just adds U8->FP16 layer in front of the model. So with FP16 input you can avoid this conversion, but the input frame will still be "U8 quality", just potentially converted to fp16, which won't add additional information to the model - so output would be the same I think.
Thanks, Erik
I couldn't find specs for the camera telling how many bits per pixel it had so I assumed it was more than 24. If it is 24 then it explains the U8 use, thanks!
The model is supposed to work on gray scale data, but it seems like that doesn't matter either then?
I have been converting what's in the python ocr example which means type BGR888p and toPlanar (from depthai-core\examples\utility). Setting the type to GRAY8 works, but if that is a single 8 bit value rather than 3x8 then toPlanar likely does the wrong thing for that.
Another strange thing is that although the python code runs fine my C++ code freezes after about 10s and never comes back (break in the debugger doesn't point to anything helpful).
I'm using 2.17.4. I tried to go back to 2.16 today, but I got a memory allocation exception for the pipeline that I couldn't figure out.
I tried both openvino 2021.2 and 2021.4 without any noticeable difference.
There seem to be some kind of "communication" issue with the OCR NN. It appears to take a long time to get output after sending some input (around 250 ms per input) and not all input gets a corresponding output.
I tried setting the log level to "trace", but I only get "info" messages about the device state.
I test with 1-4 detection areas so the input queue shouldn't really be an issue.
I got old versions building with my project and tested them out with OCR using openvino 2021.4.
As it turns out it's only 2.17.4 that doesn't work. It works as expected with 2.17.3 and earlier.
I also tried openvino 2022.1 with 2.17.3 and that still gives the warning for OCR - [warning] Input image (120x32) does not match NN (1x120).